‘乌台诗案’后,在旧年除夕,苏东坡被释放出狱。出了东城街北面的监狱大门,他停了一会儿,用鼻子嗅了嗅空气,感觉到了微风吹到脸上的快乐,在喜鹊吱喳叫声中,看见行人在加上骑马而过。他真是积习难改,当天他又写了两首诗。一首诗里面说:平生文字为吾累,辞去声名不厌低。塞上纵归他日马,城东不斗少年鸡。
后来去黄州,安定下来后,开始思考人生的意义,毕竟他死里逃生。他开始沉淀自己的个性,转向佛老思想,于是就有了,<<安国寺记>>:
元丰二年十二月,余自吴兴守得罪,上不忍诛,以为黄州团练副使,使思过而自新焉。其明年二月至黄。舍馆粗定,衣食稍给,闭门却扫,收招魂魄,退伏思念,求所以自新之方。反观从来举意动作,皆不中道,非独今以得罪者也。欲新其一,恐失其二,触类而求之,有不可胜悔者,于是喟然叹曰:“道不足以御气,性不足以胜习。不锄其本,而耘其末,今虽改之,后必复作,盍归诚佛僧求一洗之?”得城南精舍曰安国寺,有茂林修竹,陂池亭榭。间一、二日辄往,焚香默坐,深自省察,则物我相忘,身心皆空,求罪垢所以生而不可得。一念清净,染污自落,表里翛然,无所附丽,私窃乐之。旦往而暮还者,五年于此矣。
寺僧曰继连,为僧首七年,得赐衣。又七年,当赐号,欲谢去,其徒与父老相率留之。连笑曰:“知足不辱,知止不殆。”卒谢去。余是以愧其人。七年,余将有临汝之行。连曰:“寺未有记,具石请记之。”余不得辞。
寺立于伪唐保大二年,始名“护国”,嘉祐八年赐今名。堂宇斋阁,连皆易新之,严丽深稳,悦可人意,至者忘归。岁正月,男女万人会庭中,饮食作乐,且祠瘟神,江淮旧俗也。四月六日,汝州团练副使眉山苏轼记。
FCNs in the Wild: Pixel-level Adversarial and Constraint-based Adaptation
介绍
这篇论文是首次将domain adaptation应用到self-driving的semantic segmentation里面,和FCN在segmentation里面是一样算是开篇之作。
abstract
Fully convolutional models for dense prediction have proven successful for a wide range of visual tasks. Such models perform well in a supervised setting, but performance can be surprisingly poor under domain shifts that appear mild to a human observer. For example, training on one city and testing on another in a different geographic region and/or weather condition may result in significantly degraded performance due to pixel-level distribution shift. In this paper, we introduce the first domain adaptive semantic segmentation method, proposing an unsupervised adversarial approach to pixel prediction problems. Our method consists of both global and category specific adaptation techniques. Global domain alignment is performed using a novel semantic segmentation network with fully convolutional domain adversarial learning. This initially adapted space then enables category specific adaptation through a generalization of constrained weak learning, with explicit transfer of the spatial layout from the source to the target domains. Our approach outperforms baselines across different settings on multiple large-scale datasets, including adapting across various real city environments, different synthetic sub-domains, from simulated to real environments, and on a novel large-scale dash-cam dataset.
摘要里面最重要的应该是这句话了,global and category specific adaptation techniques,后面会详细介绍。
Fully Convolutional Adaptation Models
source domain and target domain
既然是涉及transfer,这里就要有source domain (源域),$S$,这里就有图片空间$I_S$和对应的标注空间$L_S$。我们训练得到$\phi_S(I_S)$。然后我们的目标是,学习一个语义分割的模型,它适用于没有被标注的目标域(target domain)$T$,有图片空间$I_T$。我们用$\phi_T()$来表示这个模型。
domain shifts
- global changes,会导致特征空间的边缘概率分布的不同
这个常常是会出现在两个不用的领域里面,两个领域的越是不同,shift会越大,比如:模拟的数据和实际数据。 - category specific parameter changes
不同类在两个不同的领域里面会有不同的偏差,比如:车和标志在不同领域里面的做迁移的时候,分布的改变会不同。
loss function
我需要假设,源域和目标域有同样的标注空间,以及源域训练得到的模型比目标域有更好的效果。
然后基于上面的shifts,我们需要两个loss function:
- $L_da(I_S, I_T)$:
这个和global的distribution distance相关 - $L_mi(I_T, P_{L_S})$:
这个和category specific parameters有关,其中,$P_{L_S}$表示的是从源域迁移过来的标注空间的概率分布
此外我们还需要一个loss function: - $L_seg(I_S, I_T)$:
这个是在源域上面的标准的监督分割的一个目标函数,就是正常的我们在source data上面训练的一个loss function而已。
所以最后的loss function:
$L(I_S, I_T, P_{L_S}) = L_{da}(I_S, I_T) + L_{mi}(I_T, P_{L_S}) + L_{seg}(I_S, I_T)$
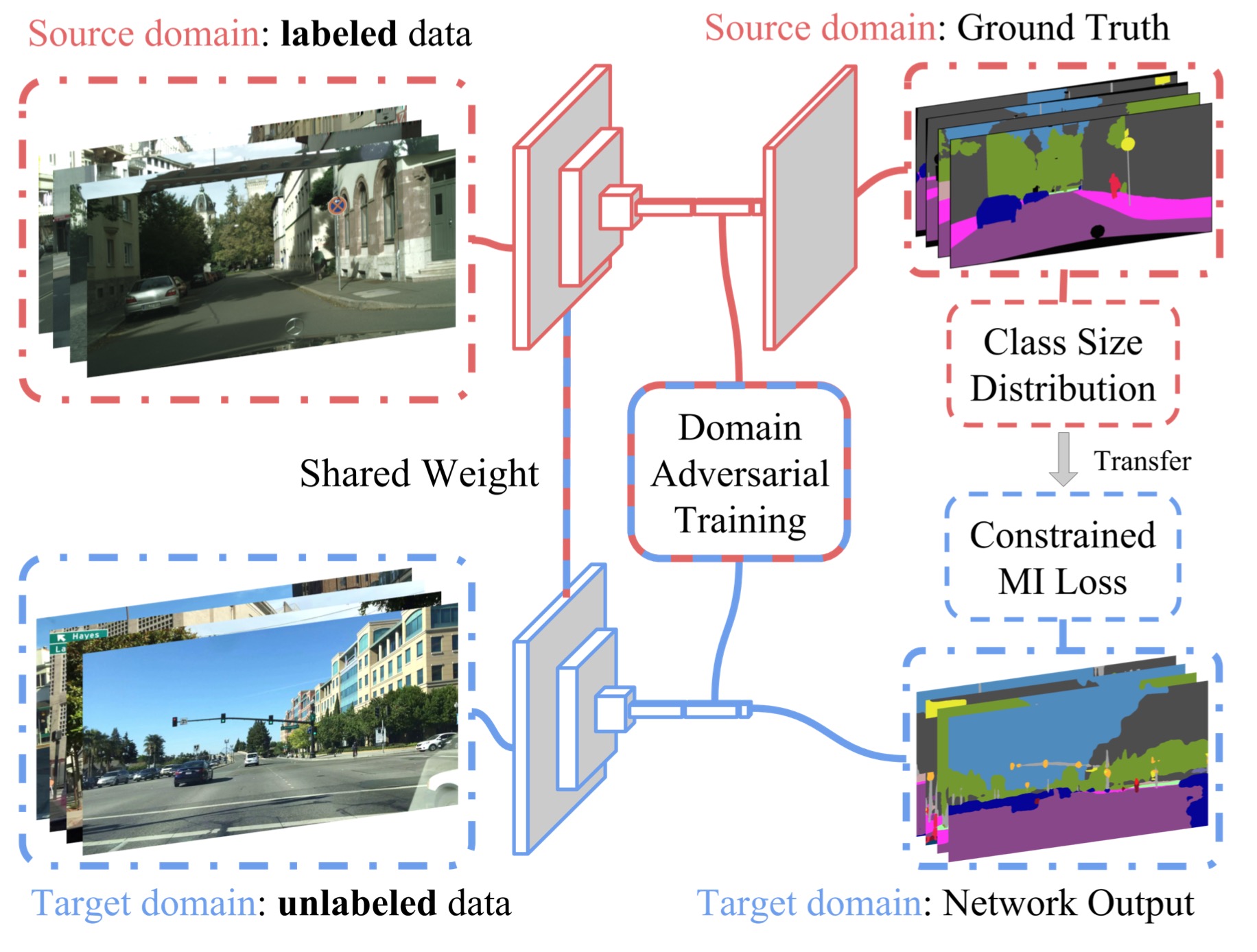
这张图很好的呈现了整个过程的pipeline,$L_{seg}(I_S, I_T)$是在source domain data上面训练的;fully-convolutional domain adversarial training则是用来降低,源和目标域概率分布不同的距离;我们又通过constrained pixel-wise multiple instance learning objective在目标域上面的数据训练,来完成category specific的更新。
Global Domain Alignment
这里我们详细阐述$L_{da}(I_S, I_T)$,然后重申一遍,我们需要减小源域和目标的域偏移,然后我们采用的是domain adversarial (域的对抗学习)的方法。
- 我们需要回答的第一个问题是:在这个密集的预测框架里面,需要由什么来组成一个实例?
回答是考虑最终一个表示层的每一个空间单元的自然接受域所对应的区域,作为独立的实例。换句话说,我们不在网络的最后一层,而是在有pixel prediction的前一层进行操作。
我们将这一层的结果用$\phi_{l-1}(\theta, I)$来表示,它对应的参数是$\theta$。 - 接下来我们来进一步拆解,我们的domain adversarial loss,它有交替的最小化目标组成。
- 一是在表示空间,我们想要最小化源域和目标域的距离:$d(\phi_{l-1}(\theta, I_S), \phi_{l-1}(\theta, I_T))$
- 二是我们需要通过训练区分源域和目标域实例的域判别器来估计这个距离,我们将判别器的参数设为$\theta_D$
我们需要让这个判别器来学习源域区域和目标域区域的不同,进而来使源域和目标域在表示空间上的距离最小。
- loss function and inverse domain loss function:
$L_D = - \sum_{I_S \in S}\sum_{h \in H}\sum_{w \in W}log(P_{\theta_D}(R_{hw}^S)) - \sum_{I_T \in T}\sum_{h \in H}\sum_{w \in W}log(1 - P_{\theta_D}(R_{hw}^T))$
$L_{Dinv} = - \sum_{I_S \in S}\sum_{h \in H}\sum_{w \in W}log(1 - P_{\theta_D}(R_{hw}^S)) - \sum_{I_T \in T}\sum_{h \in H}\sum_{w \in W}log(P_{\theta_D}(R_{hw}^T)) $- $P_{\theta_D} = \sigma(\phi(\theta_D, x))$
- output layer l-1: $H \times W$ spatial units
- $R_{hw}^S = \phi_{l - 1}(\theta, I_S)_{hw}$ denote source representation of each unit
- $R_{hw}^T = \phi_{l - 1}(\theta, I_T)_{hw}$ denote target representation of each unit
然后有了这些定义,我们来交替优化这两个目标函数了:$\min_{\theta_D} L_D$,$\min_{\theta} \frac{1}{2}[L_D + L_{Dinv}]$ 前者是学习相关图片域里面最有可能的域分类器,
苏子进京
感觉写写字还能让自己有活过来的感觉。
苏子少慧,有家学渊源,苏家一门三学士,还有当时宽松的社会风气,养育了我们的苏子。进京赴试,得到主考官欧阳修的赏识,得中进士。又遭母丧,守孝三年。后举家进京,遍访名仕,苏家兄弟二十有余,轻松愉快,壮志凌云,才气纵横。好羡慕苏子,二十有余开始了自己的事业,自己的话,还需要沉下心来,好好积累。所幸,找到了自己的方向吧。愿为千里驹,为君车前行千里,奋霞奔驰。
又一个开始
所有课程结束后的一周了,找了几个老师,然后收了一波拒信。然后,渐渐感受到了孤独。
身边的人都去工作了,剩下我一个人了;然后,自己的方向也不清楚,也不知道未来会怎么样。
前方就像深海,自己在一条小船上飘荡。一种空虚,一种痛苦会慢慢折磨你,看动漫,出去玩,
和别人聊天无法排遣的痛苦。只想做点什么,做做事情。做事情,也不知道如何去抉择。
又要重新去尝试,也许走了一段后会发现,只是从来没有体验过的旅程吧。但是我还是不想放弃吧。:)
数学篇
在知乎看了顾颜大神的回答,本科修了十几门数学学院的课,回头看自己感觉自己真是惭愧。虽然本科学物理的,但是学校底子差了点,不过还是有意识的会去数学学院蹭蹭课。这里希望自己可以慢慢拾起一些学过基本的东西,以及记录未来会和自己方向贴近的东西。庄子说,生有涯,学无涯,我这个人比较笨,就慢慢来吧。也不可能把所有基础的数学理论在很短的时间里面过一遍,这个过程自己也要慢慢的探索。
古文篇
从高中开始接触文言文,学习课本里面的论语,还有一些古代大家的名篇,之后,买了《史记》,《古文观止》,《浮生六记》,《韩非子》。。。粗粗的看了看,再之后,试着把古文结合到高考作文里面,有趣的是自己通过这种方式在一次模拟考,拿了全级第一(并列的)。然后,这个兴趣一直保留到了现在,最近还在看《战国策》,一点点领略春秋战国时候的纵横捭阖。我感觉悠悠几千年的文化,很多东西都是通过这种文风传承下来。自己的一些基本观念思想,自己处世的一些原则,自己对于逆境是如何看待的无一不受到了这些古圣昔贤的影响。所以,这里自己兴许会重温和继续阅读这些,慢慢记录自己的一些思考,但求阅后所感,有个地儿可以留存就好。
近来有所不顺,看欧阳修贬谪作《醉翁亭记》,范仲淹贬谪作《岳阳楼记》,苏子贬谪作《赤壁赋》,他们豁达从容,坦然面对困境,是很值得我去学习的。我最喜欢苏轼了,“为山上之清风与山间之明月,耳得之而为声,目遇之而成色”。哈哈,时临夏日,倘若有友人和我乘舟同行,在蝉鸣声中一睹河畔落日,谈天说地,岂不美哉。
机器学习篇
来CMU一个学期,为了找工作,先是选了一门系统课ds,一门项目可web,一门刷题课java. 然后,结合web TA 姚神的建议下,感觉自己还是更想走更贴近自己背景的方向,机器学习。
然后,这学期选了 introduction to machine learning, 在ml这边相当于 15-513 这样子的入门课,后续课程有很多 10-702 statistic machine learing, 10-703 deep reinforcement learning control, 10-707 introduction to deep learning, 10-708 graphical model, 10-725 convex optimization …
然后,田渊栋说,专家和民科的区别在于系不系统,这里的系不系统在我的理解是,用自己的方式去整理一遍自己所学的东西,内化成自己身体的一部分。其实,从本科学习力学开始,感觉自己只是一味的做题目,并没有去好好自己思考一遍自己学的东西,记得量子力学衣老师和自己说过,一个东西如果你懂了,过十年,你还是记得。鄙人不才,研究生阶段才第一次接触这个博客这个东西,希望通过这种方式,慢慢梳理有关ml的东西,形成自己的理解,希望一触那种,过十年也不会忘的境界。有不对之处,望诸君指正。