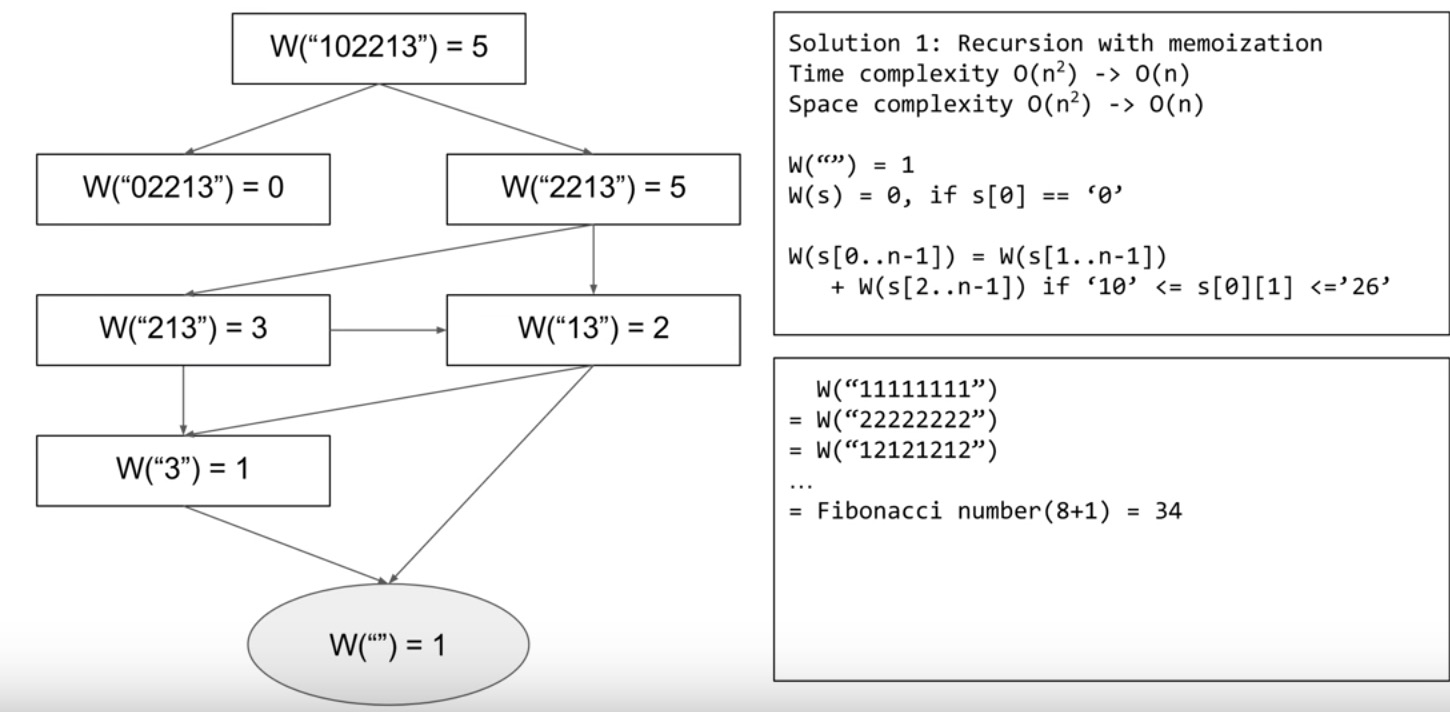
311. Sparse Matrix Multiplication
Given two sparse matrices A and B, return the result of AB.
You may assume that A’s column number is equal to B’s row number.
Example:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18Input:
A = [
[ 1, 0, 0],
[-1, 0, 3]
]
B = [
[ 7, 0, 0 ],
[ 0, 0, 0 ],
[ 0, 0, 1 ]
]
Output:
| 1 0 0 | | 7 0 0 | | 7 0 0 |
AB = | -1 0 3 | x | 0 0 0 | = | -7 0 3 |
| 0 0 1 |
Idea
normally,1
2
3
4for i in range(n):
for j in range(m):
for k in range(k):
C[i][j] = A[i][k] * B[k][i]
In fact, this is same as1
2
3
4for i in range(n):
for k in range(k):
for j in range(m):
C[i][j] = A[i][k] * B[k][i]
In this form, each A[i][k] may multiply a row of B, when a is 0, we can ignore it. What’s more, we can record the indexes of non-zero elements in a row of B, which also fasten the computation.
Code
1 | class Solution(object): |