RNN
Motivation
If our inputs and outputs are sequences, the structure of the DNN may vary due to different length of inputs and outputs. Also, traditional DNN may not abstract the temporary feature from the sequences. So, a new network which include information flow from previous states and share the weight in each single local structure may achieve our requirements.
Structure
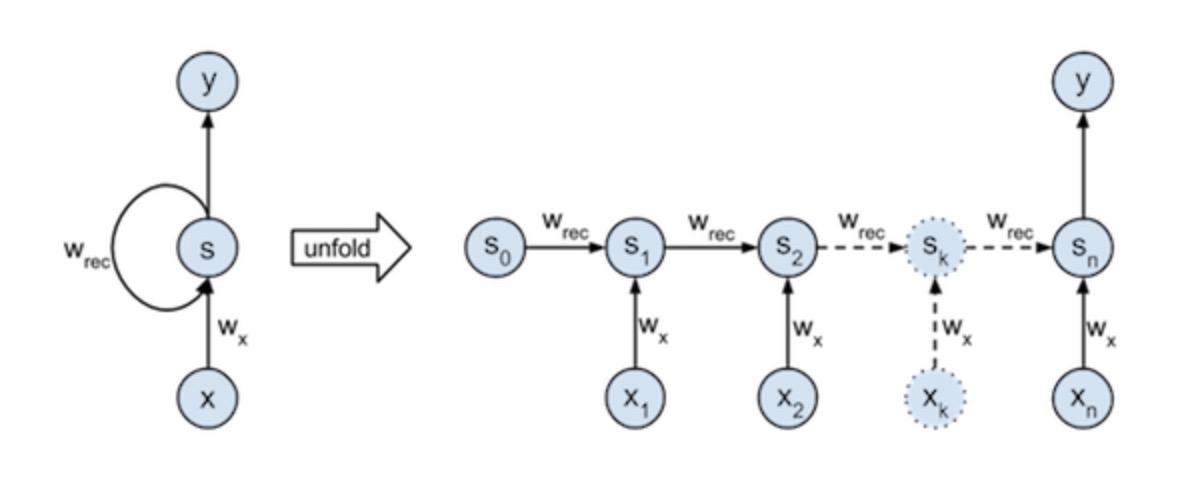
BPTT
Implementation
Dataset Define
1 | # Create dataset |
forward
1 | # Define the forward step functions |
back-progapation
1 | def output_gradient(y, t): |
Problem
If you regard each layer in time flow as a layer in DNN, then the RNN somehow is a kind of DNN, while there’s an input in each layer. The BP of RNN (BPTT) is very similar to BP in DNN. Thus, if the length of RNN is large enough, then BPTT may suffer from gradient explosion and gradient vanishing.
Solution
gradient explosion:
The clipping may solve the problem of explosiongradient vanishing:
We may need modification of the traditional RNN structure. Thus, GRU and LSTM came into being.
LSTM
The chain rule results in vanishing, thus, if we change this structue into combination of sum terms.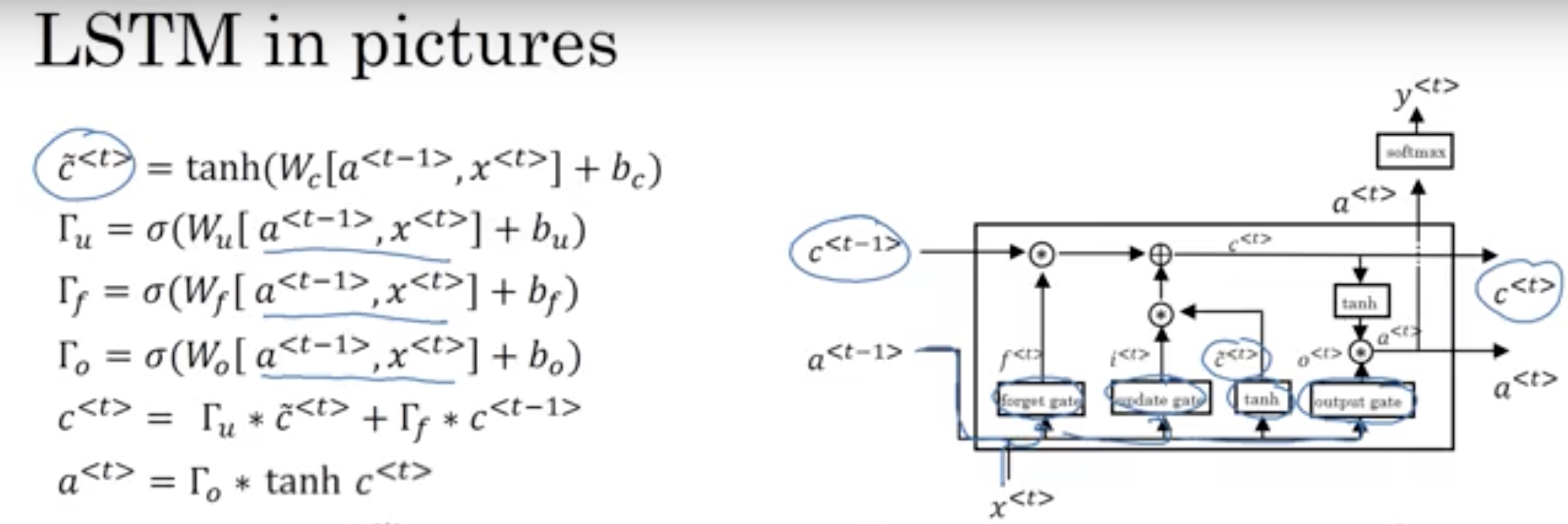
The cell state in LSTM is linear combination of current state and previous state, which avoid the gradient vanishing.
GRU
The GRU simplifies the output and remove forget gate in LSTM.