Network Structure and Training
Discriminator
For the discriminator, we use an architecture similar to but utilize all fully-convolutional lay- ers to retain the spatial information.
总是来说就是,5层卷积网络,kernel是4 x 4 stride是2,channel是{64, 128, 256, 512, 1}。
除了最后一层卷积层,其他所有层都是用参数为0.2的leaky ReLU。在最后一层卷积层之后加了一个up-sampling的层,使得最后一层和输入图片的大小是一样的。他们没有使用batch-normalization层,因为他们用小的batch size一起训练判别器和分割网络。(?)
- batch normalization:
Segmentation Network
他们用DeepLab-v2 和 ResNet-101来作为他们分割的baseline,由于memory的问题,他们没有使用multi-scale。
他们去掉了最后的分类的一层,然后将最后的两层卷积stride从2改成1。这使得输出的feature maps是输入图片大小的1/8。为了使这个更大,他们在conv4和conv5用了stride分别是2,4的dilated conv。这后面又用了Atrous Spatial Pyramid Pooling (ASPP)作为最后的分类器。在ASPP后面,他们也采用了输出的是softmax的up-sampling层,这层输出的大小和输入的图片大小也是一样的。
- ASPP:
Multi-level Adaptation Model
上面的构成了他们single-level的网络结构。为了构建multi-level的结构,他们将conv4的feature map和一个作为辅助分类器的ASPP模块相结合。和single-level类似,这里面也加了一个同样结构的判别器来进行对抗学习。如图: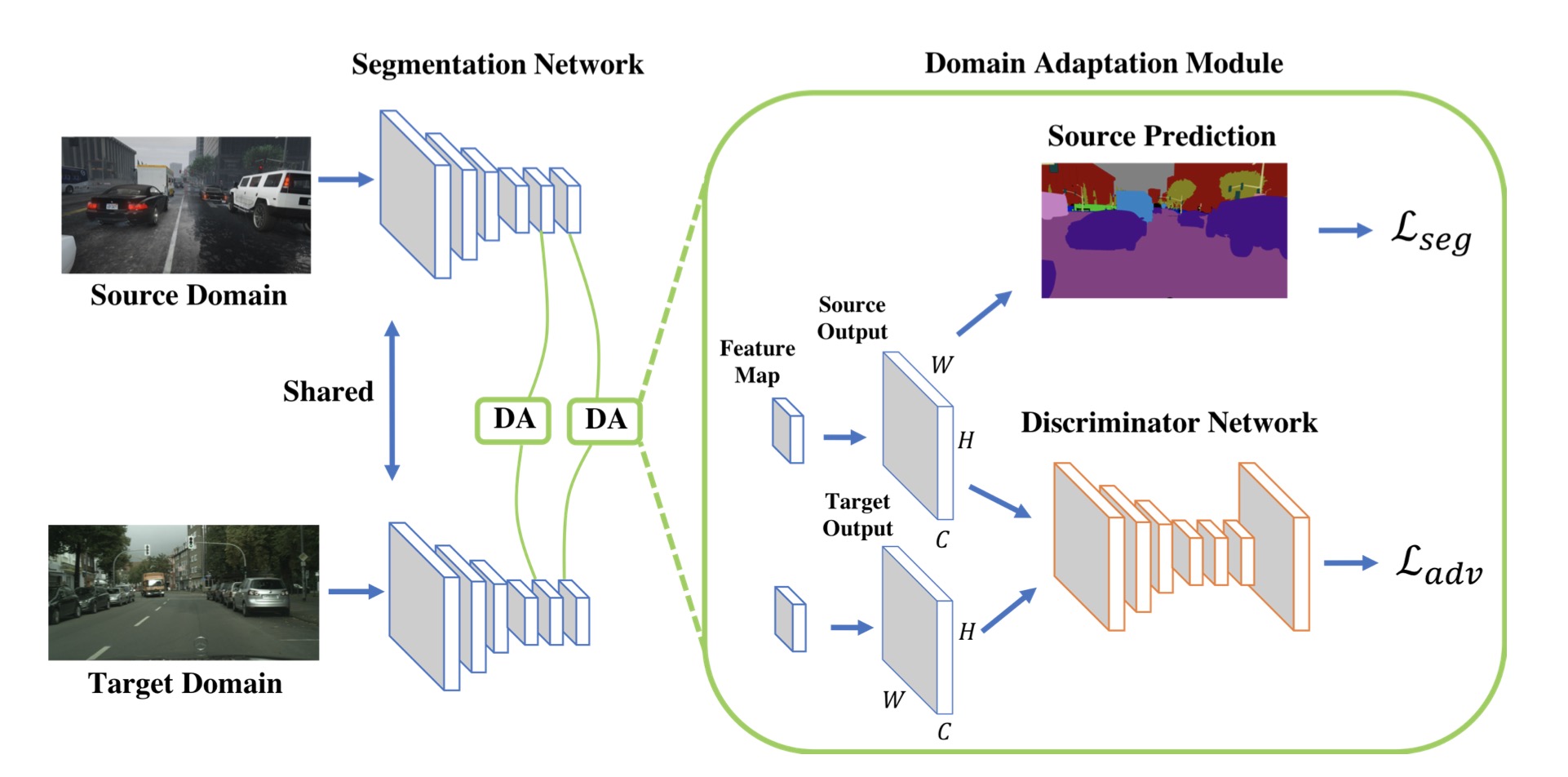
Train
作者发现,将segmentation network和discriminitor一起训练效率会比较高。
对源域将图片$I_s$向前传最后得到$P_s$,以及优化$L_{seg}$。对于目标域,我们将得到的$P_t$和$P_s$一起输入到判别器里面,然后优化$L_{d}$。此外,对于$P_t$,我们还需要计算对抗损失$L_{ad}$。
Loss Function
whole objective:
$L(I_s, I_t) = L_{seg}(I_s) + \lambda L_{adv}(I_t)$- $L_{seg}(I_s)$
cross-entropy loss using ground truth annotations in the source domain - $L_{adv}$
对抗损失,用来使得源域的预期的数据分布和目标域相近 - $\lambda_{abv}$
这个weight用来平衡这两个loss
- $L_{seg}(I_s)$
discriminitor:
segmentation softmax output:
$P = G(I) \in R^{HxWxC}$, 这里C是种类数,这里C是19cross-entropy loss:
我们将P传到全卷积的判别器D里面:$L_d(P) = - \sum_{h, w}((1 - z)log(D(P)^{(h,w,0)})) + zlog(D(P)^{(h,w,1)})$,这个是binary cross entropy,这里z = 0,表示来自target,z = 1表示来自source
segmentation network:
- segmentation loss:
在源域的话我们正常训练,还是由cross-entropy loss来定义:$L_{seg}(I_s) = -\sum_{h, w}\sum_{c \in C}Y_s^{h,w,c}log(P_s^{(h,w,c)})$ - adversarial loss:
在目标域,我们的对抗损失是:$L_{adv}(I_t) = -\sum_{h,w}log(D(G(I_t)))^{(h,w,1)}$,这个损失是用来欺骗判别器的,使得两者的预期的概率的一致
- segmentation loss:
multi-level:
- multi-level loss
就是在low-level的feature space里面加上上面的loss,也不是很难理解:
$L_{I_s, I_t} = \sum_i \lambda_i^{seg}L^i_{seg}(I_s) + \sum_i \lambda^i_{adv}L_{adv}^i(I_t)$,i表示第几层网络。
- multi-level loss
Network Code
Discriminitor
1 | import torch.nn as nn |
有了上面的描述,判别器的网络还是很清楚的。
Segmentation Network
1 | class ResNetMulti(nn.Module): |
前面应该是对resnet的结构的继承吧,后面的layer5,和layer6应该就是前面说的ASPP的classifier了,这两个分别之后参与adaptation module的部分。
Train Code
Train G
类似train 原本的GAN,这里train的G其实就是segmentation network
Train with source
1 | _, batch = trainloader_iter.next() |
train with source这里的loss就是:$\sum_i \lambda_i^{seg}L^i_{seg}(I_s)$,$L_{seg}(I_s) = -\sum_{h, w}\sum_{c \in C}Y_s^{h,w,c}log(P_s^{(h,w,c)})$
Train with target
1 | _, batch = targetloader_iter.next() |
train target对应的就是:$\sum_i \lambda^i_{adv}L_{adv}^i(I_t)$,$L_{adv}(I_t) = -\sum_{h,w}log(D(G(I_t)))^{(h,w,1)}$
Train D
Train with source
1 | # labels for adversarial training |
$L_d(P) = - \sum_{h, w}((1 - z)log(D(P)^{(h,w,0)})) + zlog(D(P)^{(h,w,1)})$,z = 0
Train with target
1 | # labels for adversarial training |
$L_d(P) = - \sum_{h, w}((1 - z)log(D(P)^{(h,w,0)})) + zlog(D(P)^{(h,w,1)})$,z = 1