abstract
Convolutional neural network-based approaches for semantic segmentation rely on supervision with pixel-level ground truth, but may not generalize well to unseen image domains. As the labeling process is tedious and labor intensive, developing algorithms that can adapt source ground truth labels to the target domain is of great interest. In this paper, we propose an adversarial learning method for domain adaptation in the context of semantic segmentation. Considering semantic segmentations as structured outputs that contain spatial similarities between the source and target domains, we adopt adversarial learning in the output space. To further enhance the adapted model, we construct a multi-level adversarial network to effectively perform output space domain adaptation at different feature levels. Extensive experiments and ablation study are conducted under various domain adaptation settings, including synthetic-to-real and cross-city scenarios. We show that the proposed method performs favorably against the state-of-the-art methods in terms of accuracy and visual quality.
introduction
model
- 1) a segmentation model to predict output results
- 2) a discriminator to distinguish whether the input is from the source or target segmentation output.
contributions
- propose a domain adaptation method for pixel-level semantic segmentation via adversarial learning
- demonstrate that adaptation in the output (segmentation) space can effectively align scene layout and local context between source and target images
- a multi-level adversarial learning scheme is developed to adapt features at different levels of the segmentation model, which leads to improved performance.
structure
感觉也不是那么难理解,就是有点像u-net,它这里的话就是在不同的layer里面用GAN,就是所谓的multi-,
然后主要是output space上面,因为这篇文章发现,不管两个domain的图多么不一样,他们在output space总是有很多相似的地方。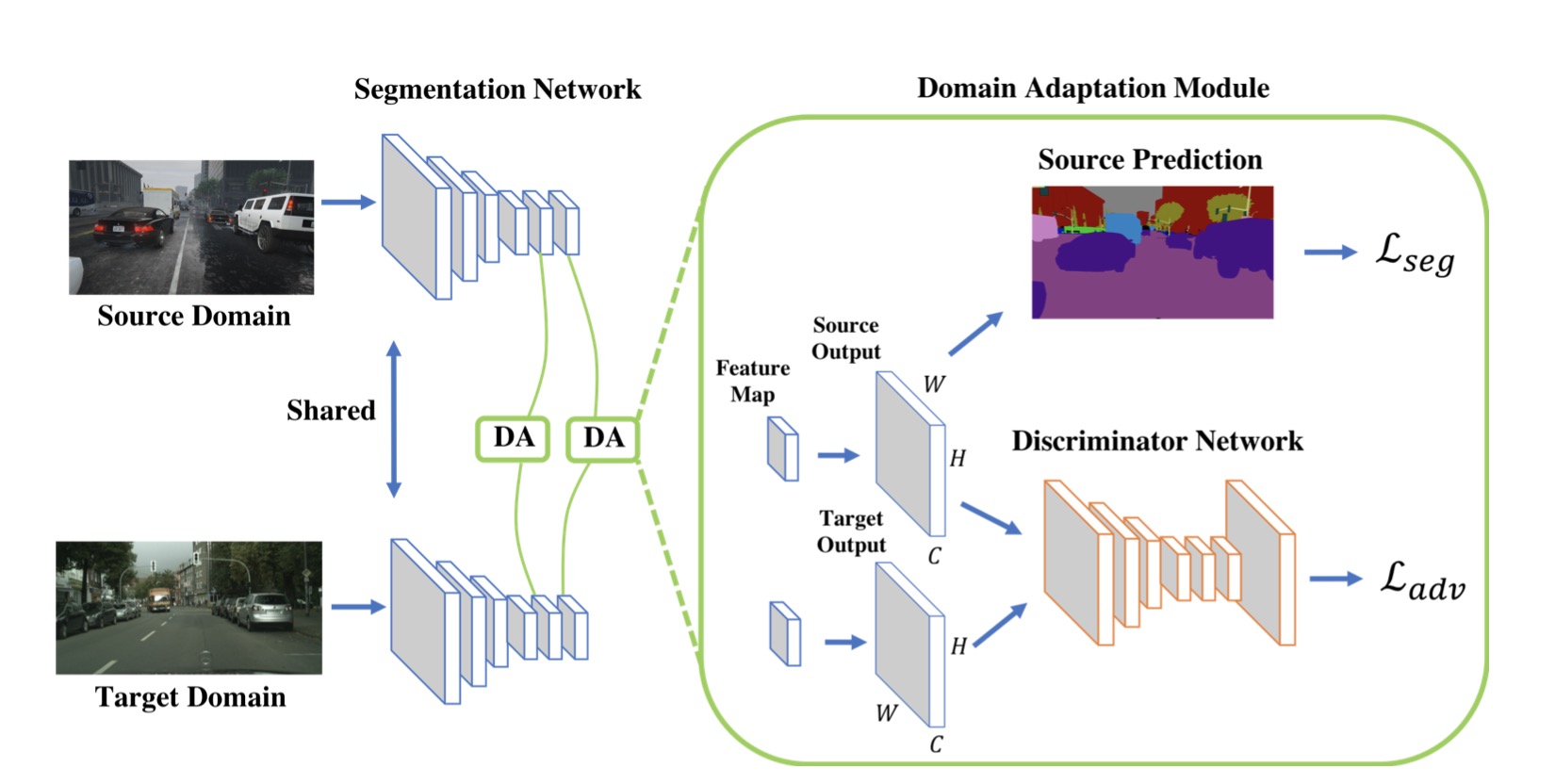
model overview
这个结构有两个模块:生成器$G$和判别器$D_i$ (i 表示是第几层的判别器)。images通过生成器出来的是源域segmentation的概率分布$P_s$
loss function
$L(I_s, I_t) = L_{seg}(I_s) + \lambda L_{adv}(I_t)$
- $L_{seg}(I_s)$
cross-entropy loss using ground truth annotations in the source domain - $L_{adv}$
对抗损失,用来使得源域的预期的数据分布和目标域相近 - $\lambda_{abv}$
这个weight用来平衡这两个loss
Output space adaptation
Single-level adversarial learning
Discriminator Training
- cross entropy
- 定义:
给定两个分布,p,q,它们在给定样本集上面的交叉熵的定义如下
$CEH(p, q) = E_p[-log q] = - \sum_{x \in X}p(x)q(x) = H(p) + D_{KL}(p||q)$,当p的熵给定时,交叉熵和KL散度是一致是的,一定程度上可以用来描述,这两个分布的距离。 - 讨论:讲到cross entropy,为什么用cross entropy loss 于分类呢?(Jackon解答)
- 比起一般的classification error 作为loss,它很更精细准确的去描述model的优劣
- 比起MSE,来说,它是一个凸优化的问题
- 定义:
segmentation softmax output:
$P = G(I) \in R^{HxWxC}$, 这里C是种类数,这里C是2,来自源域或者来自目标域cross-entropy loss:
我们将P传到全卷积的判别器D里面:$L_d(P) = - \sum_{h, w}((1 - z)log(D(P)^{(h,w,0)})) + zlog(D(P)^{(h,w,1)})$
Segmentation Network Training
- segmentation loss:
在源域的话我们正常训练,还是由cross-entropy loss来定义:$L_{seg}(I_s) = -\sum_{h, w}\sum_{c \in C}Y_s^{h,w,c}log(P_s^{(h,w,c)})$ - adversarial loss:
在目标域,我们的对抗损失是:$L_{adv}(I_t) = -\sum_{h,w}log(D(G(I_t)))^{(h,w,1)}$,这个损失是用来欺骗判别器的,使得两者的预期的概率的一致
Multi-level Adversarial Learning
- multi-level loss
就是在low-level的feature space里面加上上面的loss,也不是很难理解:
$L_{I_s, I_t} = \sum_i \lambda_i^{seg}(I_s) + \sum_i \lambda^i_{adv}L_{adv}^i(I_t)$,i表示第几层网络。 - whole picture
有了上面的对loss的介绍后,我们的问题其实就是一个min-max的优化问题:
$max_D min_G L(I_s, I_t)$