最近在做迁移学习,这篇是我们学校的大佬做的工作,看下总结一下:
abstract
Recent advances in vision tasks (e.g., segmentation) highly depend on the availability of large-scale real-world image annotations obtained by cumbersome human labors. Moreover, the perception performance often drops signif- icantly for new scenarios, due to the poor generalization capability of models trained on limited and biased annota- tions. In this work, we resort to transfer knowledge from automatically rendered scene annotations in virtual-world to facilitate real-world visual tasks. Although virtual-world annotations can be ideally diverse and unlimited, the dis- crepant data distributions between virtual and real-world make it challenging for knowledge transferring. We thus propose a novel Semantic-aware Grad-GAN (SG-GAN) to perform virtual-to-real domain adaption with the ability of retaining vital semantic information. Beyond the sim- ple holistic color/texture transformation achieved by prior works, SG-GAN successfully personalizes the appearance adaption for each semantic region in order to preserve their key characteristic for better recognition. It presents two main contributions to traditional GANs: 1) a soft gradient-sensitive objective for keeping semantic boundaries; 2) a semantic-aware discriminator for validating the fidelity of personalized adaptions with respect to each semantic region. Qualitative and quantitative experiments demonstrate the superiority of our SG-GAN in scene adaption over state- of-the-art GANs. Further evaluations on semantic seg- mentation on Cityscapes show using adapted virtual im- ages by SG-GAN dramatically improves segmentation per- formance than original virtual data.
related work
真是牛逼,总结的超级好:
Previous domain adaption approaches can be summarized as two lines: minimizing the difference between the source and target feature distributions [12, 15, 16, 17, 18, 36]; or explicitly ensuring that two data distributions close to each other by adversarial learning [24, 26, 27, 34, 42, 44] or feature combining [10, 11, 22, 25, 37].
Image-based adaptation can be also referred to as image-to-image translation, i.e., translating images from source domain to target domain, which can be summarized into two following directions.
the problem to solve
传统的GAN的问题是尽管可以实现从源域到目标域图片颜色和文理的迁移,但是会忽视关键区域的一些特征(这些特征和颜色文理有什么区别)。
whole picture
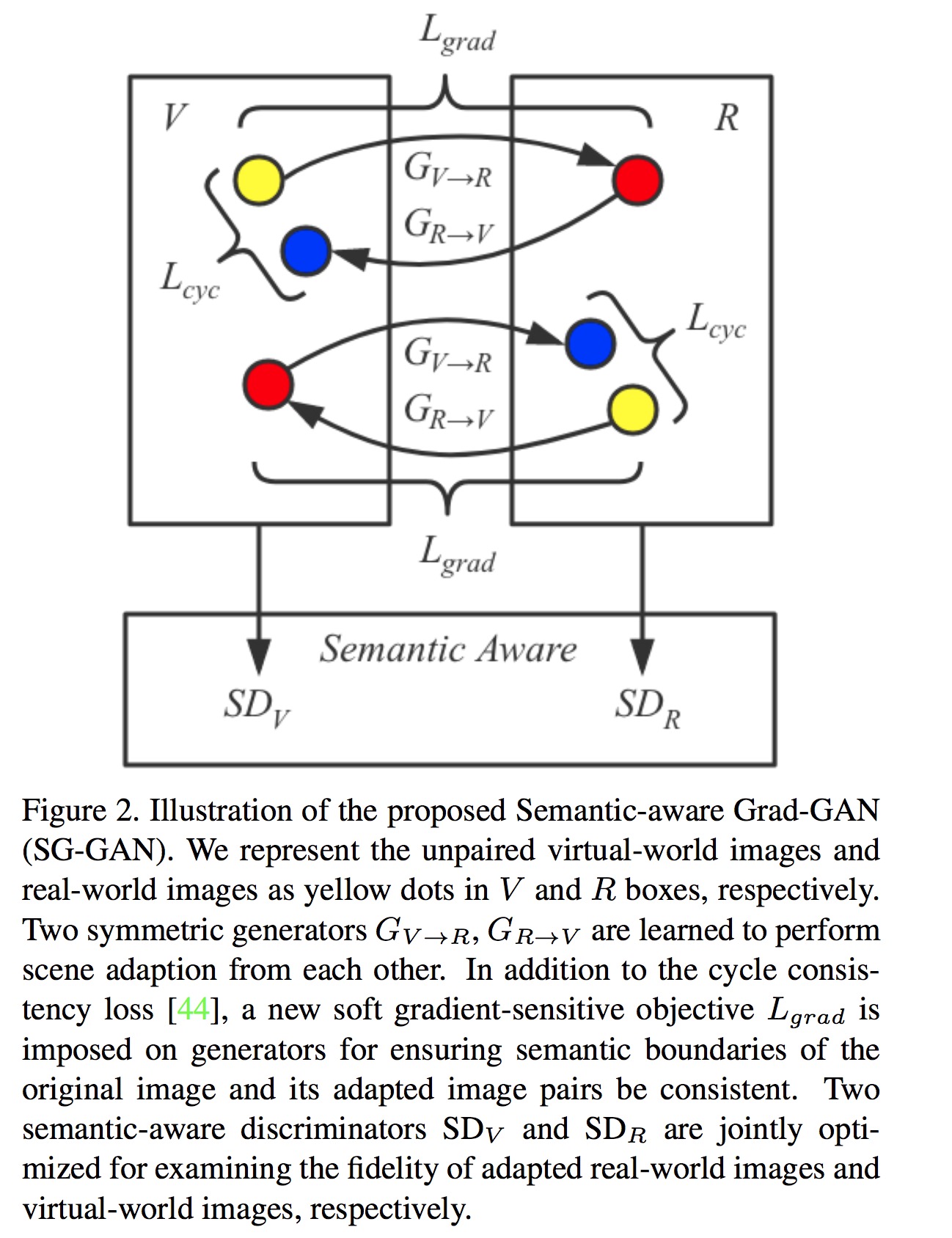
loss objective
下面对里面涉及的loss进行拆解
adversarial loss
首先这里是基于标准的对抗损失,这里我先重温一下GAN里面的基本loss function:
$min_G max_D V(D, G) | V(D, G) = E_{x~p_{data}(x)}[log D(x)] + E_{z_{p_{z}(z)}}[log(1 - D(G(z)))]$
Generative Adversarial Network 的基本思想,生成网络G想要使得V尽量小,而判别网络D想要使得V尽量大,然后二者一直在对抗。
这里有一张图很好的对此做了说明: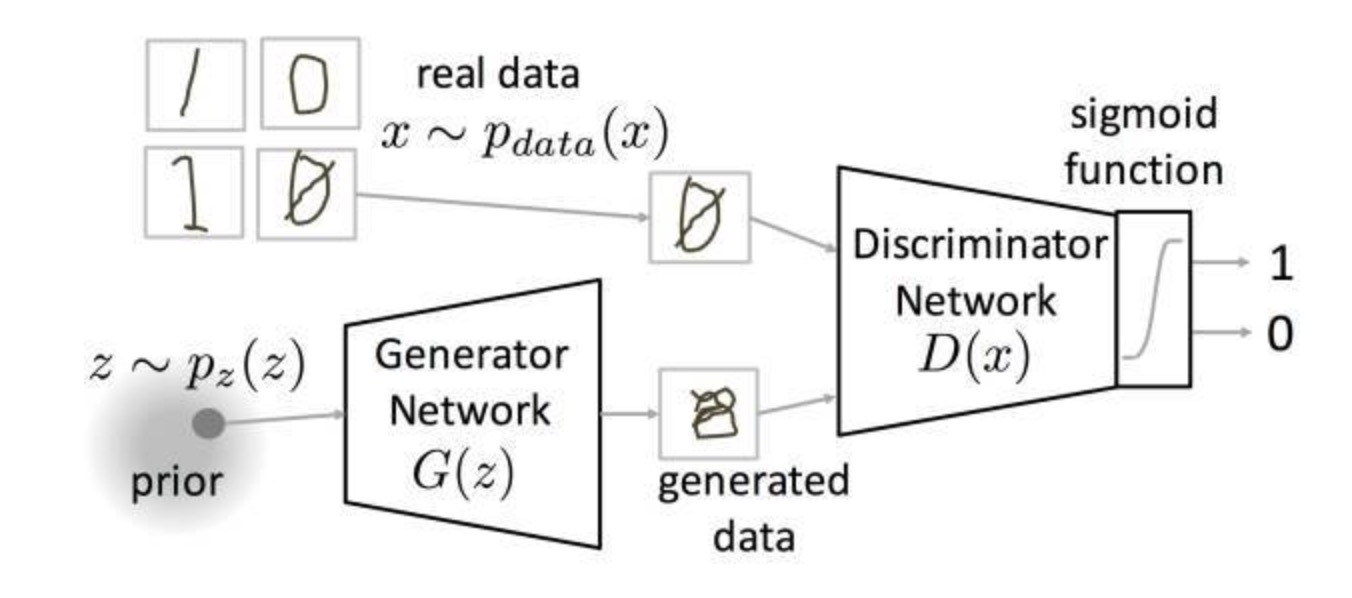
我们从real data的分布里面sample得到一个图,我们有一个fake的数据分布$z~p_z(z)$,经过我们的生成网络生成一张图,然后这两张图,分别传到判别网络里面判断,输出0或者1。
cycle consistency loss
如果看过我之前写的cycle-GAN的分析这个就很好理解了。作者也说了,他们也是基于cycle-GAN来改进的。
Soft gradient-sensitive objective
这个和edge detector有关。